Does the residual plot show that the line of best fit is appropriate for the data?

Answers
A residual plot alone does not provide a definitive answer about the appropriateness of the line of best fit. It should be used in conjunction with other diagnostic tools, such as examining the regression coefficients, goodness-of-fit measures (e.g., R-squared), and conducting hypothesis tests.
The residual plot is a graphical tool used to assess the appropriateness of the line of best fit or the regression model for the data. It helps to examine the distribution and patterns of the residuals, which are the differences between the observed data points and the predicted values from the regression model.
In a residual plot, the horizontal axis typically represents the independent variable or the predicted values, while the vertical axis represents the residuals. The residuals are plotted as points or dots, and their pattern can provide insights into the line of best fit.
To determine if the line of best fit is appropriate, you would generally look for the following characteristics in the residual plot:
Randomness: The residuals should appear randomly scattered around the horizontal axis. If there is a clear pattern or structure in the residuals, it suggests that the line of best fit is not capturing all the important information in the data.
Constant variance: The spread of the residuals should remain relatively constant across the range of predicted values. If the spread of the residuals systematically increases or decreases as the predicted values change, it indicates heteroscedasticity, which means the variability of the errors is not constant. This suggests that the line of best fit may not be appropriate for the data.
Zero mean: The residuals should have a mean value close to zero. If the residuals consistently deviate above or below zero, it suggests a systematic bias in the line of best fit.
It's important to note that a residual plot alone does not provide a definitive answer about the appropriateness of the line of best fit. It should be used in conjunction with other diagnostic tools, such as examining the regression coefficients, goodness-of-fit measures (e.g., R-squared), and conducting hypothesis tests.
For such more questions on Residual plot assesses appropriateness.
https://brainly.com/question/3297603
#SPJ8

Related Questions
Determine the domain and the range of the function.
f = {(8, 4), (21, -5), (45, 4), (53, 10)}
Answers
Answer:
Step-by-step explanation:
brainliest pls? :)

A package of 4 pairs of insulated socks costs $22.36 . What is the unit price of the pairs of socks ?
Answers
Answer:
5.59
Step-by-step explanation:
22.36/4 = 5.59
hope this helps!
1+1+1-1-5-5r-3-3--2-6--4
Answers
Step-by-step explanation:
1 + 1 + 1 - 1 - 5 - 5r - 3 - 3 --2 - 6 --4
3 - 1 - 5 - 5r - 3 - 3 -- 2 - 6 -- 4
2 - 5 - 5r - 3 - 3 -- 2 - 6 -- 4
-3 - 5r - 3 - 3 -- 2 - 6 -- 4
-5r - 6 - 3 + 2 - 6 + 4
-5r - 9 + 2 - 6 + 4
-5r - 7 - 6 + 4
-5r -13 + 4
-5r - 9
This is the furthest it can be reduced to if you're not trying to find the value of r.
Hope this helps! :)
assume that the numbers 1,2,...,n are randomly given to players labeled 1,2,...,n. initially, player 1 and player 2 compare their numbers. the one with the largest number wins and compares her number with player 3, and so on. find the probability that player 1 wins m times.
Answers
The probability that player 1 wins m times is \($\frac{m}{n}\).
Assume that the numbers 1,2, ....., and n are randomly given to players.
Consider,
\(\Omega & =\{1,2, \ldots, n\} \\\)
\(& =\left\{\omega_1, \omega_2, \ldots, \omega_n\right\}\)
Here, player 1 and player 2 compare their numbers.
The one with the largest number wins and compares her number with player 3 and So on...
If all outcomes are equally likely,
\(\Omega=\left\{\omega_1, \omega_2, \ldots . ., \omega_n\right\}\)
Then \($\Omega$\) is equiprobable sample space.
The probability of each \($\omega_i$\) is \($\frac{1}{n}\) for i = 1, 2, ..........., n
\($P\left\{w_1\right\}=P\left\{\omega_2\right\}=P\left\{\omega_3\right\}............P\left\{\omega_n\right\} = \frac{1}{n}\)
These numbers are randomly given then it has m Sample points.
Probability = P (player 1 wins m times)
For every subset of numbers chosen uniformly at random all possible permutations of these numbers are equally likely.
\($\Rightarrow P(A)=\frac{1}{n}+\frac{1}{n}+\cdots \cdots+\frac{1}{n} \text { ( mimes) }\)
The number of sample points in A is divided by a number of Sample points in \(} \Omega}$\).
\($=\frac{\text { number of sample points in } A}{\text { number of Sample points in } \Omega}\)
\($=\frac{\text { number of favorable cases to event } A}{\text { number of possible cases }}$\)
\($=\frac{m}{n} \\\)
Therefore P(A) = \($\frac{m}{n}\)
For more questions on probability
https://brainly.com/question/19550507
#SPJ4
how many distinguishable ways can you arrange the letters in the word internet? show the work that leads to your answer.
Answers
There are 5040 distinguishable ways to arrange the letters in the word "internet".
The word "internet" is made up of 8 letters, including two "n"s, two "t"s, and one of each of the other letters. We may use the formula for permutations with repetition to find the number of recognizable ways to arrange the letters, which is:
n!/n1!n2!...nk!
where n is the total number of objects to be arranged, and n1, n2, ..., nk are the frequencies of each of the k distinct objects. In this case, we have:
n = 8
n1 = 2 (for the "n"s)
n2 = 2 (for the "t"s)
n3 = 2 ( for the "e"s)
and n3 = n4 = n5 = 1 (for the remaining letters).
Substituting these values into the formula, we get:
8!/2!2!2!
= 8x7x6x5x4x3x2x1 / (2x1)(2x1)(2×1)
= 5040
Therefore, there are 5040 distinguishable ways to arrange the letters in the word "internet".
Learn more about Permutation:
https://brainly.com/question/28065038
#SPJ4
lena is going to rent a truck for one day. there are two companies she can choose from, and they have the following prices. company a charges and allows unlimited mileage. company b has an initial fee of and charges an additional for every mile driven. for what mileages will company a charge less than company b? use for the number of miles driven, and solve your inequality for .
Answers
Therefore, company A will charge less than company B for any mileage greater than 65 miles.
To help you with your question, I need the specific prices for both companies, as well as any additional information you can provide about the charges.
To solve for the mileages at which company A will charge less than company B, we can set up the following inequality:
A < B
where A is the cost of renting from company A and B is the cost of renting from company B. We can plug in the given information to get:
x ≤ A
x > B = y + 40z
where x is the number of miles driven, y is the initial fee for company B, and z is the additional cost per mile for company B.
Now we can substitute the given values to get:
x ≤ A
x > y + 40z
For company A, the cost is a flat rate with unlimited mileage, so A is just the cost listed for one day of rental. Let's say that cost is $100.
For company B, the initial fee is $50 and the additional cost per mile is $0.25. So:
y = 50
z = 0.25
Now we can plug in these values and solve for x:
x ≤ 100
x > 50 + 40(0.25)
x > 65
Therefore, company A will charge less than company B for any mileage greater than 65 miles.
To help you with your question, I need the specific prices for both companies, as well as any additional information you can provide about the charges.
learn more about charge here :https://brainly.com/question/14692550
#SPJ11
Which of the following differential equation(s) is/are linear? (Choose all that apply.) 1 2xy" - 5xy' + y = sin(3x) (v)² + xy =In(x) □y' + sin(y)=e3x (x²+1)y"-3y - 2x³y=-x-9 (+1)y'+xy=y"
Answers
To determine which differential equation(s) are linear, we need to examine the form of each equation. A linear differential equation is one that can be written in the form a(x)y" + b(x)y' + c(x)y = g(x), where a(x), b(x), c(x), and g(x) are functions of x.
The differential equation 2xy" - 5xy' + y = sin(3x) is linear. It can be written in the form a(x)y" + b(x)y' + c(x)y = g(x), where a(x) = 2x, b(x) = -5x, c(x) = 1, and g(x) = sin(3x).
The differential equation (v)² + xy = In(x) is not linear. It does not follow the form a(x)y" + b(x)y' + c(x)y = g(x) because it contains a term with (v)², where v represents the derivative of y with respect to x. This term does not have a linear coefficient.
The differential equation y' + sin(y) = e^(3x) is linear. It can be written in the form a(x)y' + b(x)y = g(x), where a(x) = 1, b(x) = sin(y), and g(x) = e^(3x).
The differential equation (x²+1)y" - 3y - 2x³y = -x - 9 is not linear. It does not follow the form a(x)y" + b(x)y' + c(x)y = g(x) because it contains a term with (x²+1)y", where the coefficient is a function of x.
The differential equation y' + xy = y" is linear. It can be written in the form a(x)y' + b(x)y = g(x), where a(x) = 1, b(x) = x, and g(x) = y".
Learn more about differential equation here
https://brainly.com/question/32524608
#SPJ11
How do you estimate a scatter plot?
Answers
Answer:
Step-by-step explanation:
1.Collect pairs of data where a relationship is suspected.
2.Draw a graph with the independent variable on the horizontal axis and the dependent variable on the vertical axis. ...
3.Look at the pattern of points to see if a relationship is obvious. ...
4.Divide points on the graph into four quadrants.
Matti is making moonshine in the woods behind his house. He’s
selling the moonshine in two different sized bottles: 0.5 litres
and 0.7 litres. The price he asks for a 0.5 litre bottle is 8€, for
a
Answers
Based on the calculation, it appears that Matti had approximately 94 bottles of 0.5 litres and 11 bottles of 0.7 litres in the last patch of moonshine that he sold.
To solve the problem using the determinant method (Cramer's rule), we need to set up a system of equations based on the given information and then solve for the unknowns, which represent the number of 0.5 litre bottles and 0.7 litre bottles.
Let's denote the number of 0.5 litre bottles as x and the number of 0.7 litre bottles as y.
From the given information, we can set up the following equations:
Equation 1: 0.5x + 0.7y = 16.5 (total volume of moonshine)
Equation 2: 8x + 10y = 246 (total earnings from selling moonshine)
We now have a system of linear equations. To solve it using Cramer's rule, we'll find the determinants of various matrices.
Let's calculate the determinants:
D = determinant of the coefficient matrix
Dx = determinant of the matrix obtained by replacing the x column with the constants
Dy = determinant of the matrix obtained by replacing the y column with the constants
Using Cramer's rule, we can find the values of x and y:
x = Dx / D
y = Dy / D
Now, let's calculate the determinants:
D = (0.5)(10) - (0.7)(8) = -1.6
Dx = (16.5)(10) - (0.7)(246) = 150
Dy = (0.5)(246) - (16.5)(8) = -18
Finally, we can calculate the values of x and y:
x = Dx / D = 150 / (-1.6) = -93.75
y = Dy / D = -18 / (-1.6) = 11.25
However, it doesn't make sense to have negative quantities of bottles. So, we can round the values of x and y to the nearest whole number:
x ≈ -94 (rounded to -94)
y ≈ 11 (rounded to 11)
Therefore, based on the calculation, it appears that Matti had approximately 94 bottles of 0.5 litres and 11 bottles of 0.7 litres in the last patch of moonshine that he sold.
for such more question on litres
https://brainly.com/question/27877215
#SPJ8
Question
Matti is making moonshine in the woods behind his house. He’s selling the moonshine in two different sized bottles: 0.5 litres and 0.7 litres. The price he asks for a 0.5 litre bottle is 8€, for a 0.7 litre bottle 10€. The last patch of moonshine was 16.5 litres, all of which Matti sold. By doing that, he earned 246 euros. How many 0.5 litre bottles and how many 0.7 litre bottles were there? Solve the problem by using the determinant method (a.k.a. Cramer’s rule).
A farmer wants to create a rectangular pen with an area of 16 m2 using the least amount of fencing. He should build the pen in the shape of a square.
Question 17 options:
A) True
B) False
Answers
B. False
The teis ut that for a population with ary distribubon, the distribuben of the sample means approaches a nermal distrbufion as the saregie size
Answers
The statement you provided is known as the Central Limit Theorem. It states that for a population with any distribution, when we take random samples of sufficiently large size (usually n ≥ 30), the distribution of sample means will approximate a normal distribution regardless of the shape of the original population distribution.
This is true as long as the sampling is done with replacement and the samples are independent.
The Central Limit Theorem is an important concept in statistics because it provides a way to use the normal distribution for inference even when the population distribution is unknown or non-normal. The theorem helps us to estimate population parameters such as the mean and standard deviation using sample statistics.
It should be noted that the approximation gets better as the sample size increases. Therefore, larger sample sizes are preferred when using the Central Limit Theorem to approximate a population distribution.
Learn more about distribution here:
https://brainly.com/question/29664127
#SPJ11
2. The perimeter of a rectangular park is 640 yards. The length of the rectangle is 40 yards less than twice the width. What are the dimensions of the park?
Answers
The dimensions of the park are obtained as 180 yards and 140yards respectively.
What is a Linear equation?A linear equation is a equation that has degree as one.
To find the solution of n unknown quantities n number of equations with n number of variables are required.
Suppose the width of the rectangle be x yards.
Then, its length is given as x - 40 yards.
Since, the perimeter of a rectangle is given as 2(l + b).
Substitute the corresponding values to get the equation as follows,
640 = 2(x - 40 + x)
=> 640 = 2(2x - 40)
=> 2x - 40 = 640/2
=> 2x - 40 = 320
=> x = 360/2 = 180
Then, the length is given as 180 - 40 = 140 yards.
Hence, the dimensions of the park are obtained as 180 yards and 140 yards respectively.
To know more about Linear equation click on,
brainly.com/question/11897796
#SPJ5
what is a simpler form of the radical expression 4 sqrt 1296 x^16y^12
Answers
So, the simpler form of the radical expression 4 sqrt 1296 x^16y^12 is 144x^14y^14 sqrt (x) sqrt (y).
To simplify the radical expression 4 sqrt 1296 x^16y^12, we need to first factor the number inside the radical. 1296 can be factored into 36 x 36, which simplifies to 6^4. So, the expression becomes 4 sqrt (6^4 x^16y^12).
Next, we can simplify the expression further by using the property of exponents that says a^m x a^n = a^(m+n). This means that we can combine the exponents of x and y, which gives us 4 sqrt (6^4 x^(16+12) y^(12+16)). Simplifying this, we get 4 sqrt (6^4 x^28 y^28).
Now, we can simplify the radical expression even further by using the property that says sqrt (a x b) = sqrt (a) x sqrt (b). Applying this to our expression, we get 4 x 6^2 x sqrt (x^28) x sqrt (y^28). Simplifying this further, we get 144x^14y^14 sqrt (x) sqrt (y).
To know more about radical visit:
https://brainly.com/question/14923091
#SPJ11
50 POINTS!!
what is the answer(s)?

Answers
Answer:
2 3/4 square yd
Step-by-step explanation:
3/1 x 11/12 = 2 3/4
The average annual rainfall in Salt Lake City, Utah, is 18.58 inches, and the average annual rainfall in New York City is 46.23 inches. What might be the reason for the difference in the cities’ average annual rainfall?
A.
Utah is close to an ocean, while New York City is landlocked.
B.
New York City is close to an ocean, while Utah is landlocked.
C.
New York City lies in a rain shadow area.
D.
New York City is closer to mountains.
Answers
Help please im trying to check my answer

Answers
Answer:
(a) 66 cm³
Step-by-step explanation:
You want the volume of a right triangular prism with a base right triangle that has a leg length of 3 cm and a hypotenuse of 5 cm. The height of the prism is 11 cm.
BaseThe base triangle is a 3-4-5 right triangle, so will have an area of ...
A = (1/2)bh
A = (1/2)(4 cm)(3 cm) = 6 cm²
VolumeThe volume of the prism is ...
V = Bh . . . . . where B is the base area
V = (6 cm²)(11 cm) = 66 cm³
The volume of the prism is 66 cubic centimeters.
__
Additional comment
As you can see, the "work" is greatly simplified by the recognition of the {3, 4, 5} right triangle. If you must use the Pythagorean theorem to find the missing side length, you will find it to be ...
b = √(c² -a²) = √(5² -3²) = √16 = 4
The answer can be estimated by realizing the missing dimension is less than 5. The volume of a rectangular prism of side lengths 3, 5, and 11 would be 3·5·11 = 165 cm³. A triangular prism with the same overall dimensions would have 1/2 that volume, or 82.5 cm³. Since the prism shown has a side length less than 5, its volume will be smaller than 82.5 cm³. The only reasonable answer is 66 cm³.
#95141404393
A hospital medical unit has 50 beds. During May, the unit provided 1,420 days of service. What was the average daily census for the medical unit in May
Answers
If a hospital medical unit has 50 beds and the unit provided 1,420 days of service, the average daily census for the medical unit in May is 28.4.
To find the average daily census for a medical unit in May, we divide the total number of days of service provided by the number of beds in the unit. Here's how we do it:
According to the question, Total number of beds = 50 and Total number of days of service = 1,420
Average daily census = Total number of days of service / Total number of beds
Average daily census = 1,420/50
Average daily census = 28.4
Therefore, the average daily census for the medical unit in May is 28.4.
Learn more about Average:
https://brainly.com/question/20118982
#SPJ11
One serving of pretzels contains 1.5 grams of fat. That is 3% of the daily amount recommended for a 2,000 calorie diet. How many grams of fat are recommended? Show your work.
Answers
Answer: 50 grams of fat
Step-by-step explanation:
From the question, we are informed that one serving of pretzels contains 1.5 grams of fat which is 3% of the daily amount recommended for a 2,000 calorie diet.
This means that we are expected to find the grams of fat for 100%. Since one serving of pretzels contains 1.5 grams of fat which is 3%, this means 1% will contain (1.5/3) = 0.5 grams of fat.
Therefore the grams of fat that are recommended will be:
= 100 × 0.5
= 50 grams of fat
Answer:
50 grams of fat
1.5 / 3 = 0.5
0.5 x 100 = 50
Step-by-step explanation:
cos(3x)=-1
1. using an appropriate inverse trigonometric expression, write an equation that defines the value of 3x.
2. solve this equation to find all possible values of the angle 3x.
3. use algebra to find all values of x between 0 and 2π that satisfy this equation.
Answers
Answer: 2 solve this equation to find all possible values of the angle 3x.
Step-by-step explanation: just took test
We solve cos(3x) = -1 using the inverse cosine function. The simplest solution is x = π/3. Accounting for the periodicity of the cosine function, we find additional solutions in the interval from 0 to 2π, specifically x = π/3 and x = 4π/3.
Explanation:In order to solve the equation cos(3x) = -1, we need to use inverse trigonometric equations and some algebraic manipulation.
We can express the equation as 3x = cos-1(-1). Cosine equals -1 at π (Pi), giving us 3x = π.From this equation, we can solve for x by dividing each side by 3. This results in x = π/3.To find all values of x between 0 and 2π that satisfy this equation, we must adjust for the periodicity of the cosine function. Cosine function has a period of 2π. Therefore, we must add multiples of the period to the original solution, 2πn/3 (n is an integer including 0). The solutions within the interval 0 to 2π are x = π/3, 4π/3.Learn more about Trigonometric Equation here:https://brainly.com/question/32300784
#SPJ2
Data collected by a price reporting agency from more than 90,000 gasoline and convenience stores throughout the U.S. showed that the average price for a gallon of unleaded gasoline was $3.28. The following data show the price per gallon ($) for a sample of 20 gasoline and convenience stores located in San Francisco.3.59 3.39 4.79 3.56 3.35 3.71 3.85 3.40 3.55 3.763.77 3.39 3.75 4.19 4.15 3.66 3.63 3.93 3.41 3.57(a) Use the sample data to estimate the mean price for a gallon of unleaded gasoline in San Francisco.(b) Compute the sample standard deviation. (Round your answer to the nearest cent.)
Answers
a. Based on the sample data, the mean price in dollars for a gallon of unleaded gasoline in San Francisco is $3.72.
b. The sample standard deviation in dollars is $0.3589.
Standard deviation,
Mean (the simple average of the numbers
Data and Calculations:
Average price of a gallon of unleaded gasoline in U.S. = $3.28
Number of gasoline and convenience stores for the U.S. average price = 90,000
Sample of San Francisco gasoline and convenience stores = 20
Prices of a gallon of gasoline in 20 San Francisco stores are as follows:
S/N. Prices Difference in Mean Difference Squared
1. $3.59 -$0.13 0.0169
2. 3.39 -0.33 0.1089
3. 4.79 1.07 1.1449
4. 3.56 -0.16 0.0256
5. 3.35 -0.37 0.1369
6. 3.71 -0.01 0.0001
7. 3.85 0.13 0.0169
8. 3.40 -0.32 0.1024
9. 3.55 -0.17 0.0289
10. 3.76 0.04 0.0016
11. 3.77 0.05 0.0025
12. 3.39 -0.33 0.1089
13. 3.75 0.03 0.0009
14. 3.79 0.07 0.0049
15. 4.19 0.47 0.2209
16. 4.15 0.43 0.1849
17. 3.66 -0.06 0.0036
18. 3.93 0.21 0.0441
19. 3.41 -0.31 0.0961
20. 3.57 -0.15 0.0225
Total $74.40 2.5765
Mean = $3.72 ($74.40/20) $0.12885 ($2.27394/20)
Standard deviation = square root of $0.12885
= $0.3589
Thus, in San Francisco, the price per gallon of unleaded gasoline is $0.03589 .
Learn more about calculating the mean and standard deviation,
brainly.com/question/10040882
#SPJ4
To find the average price of unleaded gasoline in San Francisco, add up all the given prices and divide by the total number of prices. The standard deviation, indicating spread around this average price, is computed by finding the square root of the average of the squared deviations from the mean.
Explanation:To estimate the mean price of a gallon of unleaded gasoline in San Francisco, you need to add up all the 20 given prices, then divide by the number of terms (20) in this case. The mean gives us the average value of the data set.
The standard deviation is a measure of how spread out the prices are from the mean. It is calculated by finding the square root of the variance, which is the average of the squared differences from the mean.
Remember, these calculations provide estimates, as the sample might not represent the entire population of gasoline prices in San Francisco. It's also important to note that external factors, such as changes in crude oil prices or regional taxes, can impact the cost of unleaded gasoline in diverse regions.
Learn more about Mean and Standard Deviation here:https://brainly.com/question/34166299
#SPJ12
Find the value of each variable. Round your answers to the nearest tenth. (Soh Coh Toa)
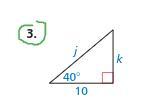
Answers
Answer:
k = 8.4, j = 13.1
Step-by-step explanation:
Solve for k:
\(tan(40)=\frac{k}{10}\\10(tan(40))=k\\8.4=k\)
Solve for j:
\(8.4^2+10^2=j^2\\70.56+100=j^2\\170.56=j^2\\13.1=j\)
Answer:
k = 10 tan (40) = 8.39 (to 2 decimals)
J = 10 / cos(40) = 13.05 (to 2 decimals)
Step-by-step explanation:
It is SOH CAH TOA, or
Sin = Opposite / Hypotenuse
Cos = Adjacent / Hypotenuse
Tan = Opposite / Adjacent
Using SOH CAH TOA,
tan(40) = k/10, so k = 10 tan (40) = 8.39 (to 2 decimals)
cos(40) = 10 / j, so J = 10 / cos(40) = 13.05 (to 2 decimals)
Help me with with this please

Answers
Answer: (4.5 , 6.5)
-11 + 20 / 2 = 4.5
14 + (-1) / 2 = 6.5
Can someone please help me with this? You've gotta prove that x=8 in a table graph thing.

Answers
Answer:
AB= AC+CB
50 = (2x – 2 ) + 4(x+1)
50 = (2x – 2) + ( 4x+4)
50 = 6x +2
6x = 50 – 2
6x = 48
x= 48/6
x= 8
So; x=8 Q.E.D.
I hope I helped you^_^
Sora correctly solved this inequality.
-2. 1w> 12.81
w<-6.1
Which graph matches the inequality?

Answers
Answer: The third one
Step-by-step explanation: open circle, with crocodile sign pointing to right which means u have to go left! Have a nice day!!
Answer:
C) a number line going from negative 6.5 to negative 5.8. An open circle is at negative 6.1. Everything to the left of the circle is shaded.
Step-by-step explanation:
Open circle means < or >
Closed circle means < or >
So has to be an open circle since the sign is <. it also says w < -6.1
so w has to be less than -6.1. So less than -6.1 would be -6.2, -6.3, -6.4etc.
PLEASE HELP WILL MARK BRAINLIEST
Find the average rate of change for the function f(x) = 3^x + 4
Using the intervals of x=2 to x=5
Show ALL your work to receive credit
Answers
Answer:
78
Step-by-step explanation:
You use the formula
\( \frac{f(b) - f(a)}{b - a} \)
with a=2 and b=5 plug it in to the formula
\( \frac{f(5) - f(2)}{5 - 2} \)
find the values
\(f(5) = {3}^{5} + 4 = 247 \)
\(f(2) = {3}^{2 } + 4 = 13\)
put it all together
\( \frac{247 - 13}{5 - 2} = \frac{234}{3} = 78\)
Which of the following expressions is equivalent to
a(4- a)- 5(a + 7) ?
A. -2a-35
B. -2a + 7
C. -a²-a-35
D.-a²-a + 7
E. -2a³-35
Answers
Answer:
c.-a²-a-35
Step-by-step explanation:
a(4-a)-5(a+7)
=4a-a²-5a-35
=a²-a-35
Graph the linear inequality y>−x−3
Answers
Answer:
see attached
Step-by-step explanation:
www desmos com/calculator
mark brainliest

Construct an outline, concept map, diagram, etc. whatever you want, for the research methodology, it should include the following points
1-My methodology
2-Experimental design
3-Approach: quantitative
4-Population: 989
5-Sample size: 402
6-Type of sampling: conglomerates
7-Research techniques: Surveys
8-Data collection: Surveys
9-Data analysis: R software
I have a doubt, because in point 7 and 8 they are different points but they have the same concepts, that is: surveys.
Explain to me why both have the same thing if they are different steps or is neccesary change something there in 7 and 8?
If you want you can add more concepts or branches in your graph.
Answers
Answer (25-30 words): In point 7 and 8, the concept of surveys is repeated because research techniques refer to the overall approach, while data collection specifically focuses on the method used to gather data.
In research methodology, point 7 refers to the research techniques employed, which in this case is surveys. Surveys are a common method for gathering data in quantitative research. Point 8, on the other hand, specifies the data collection process, which again involves the use of surveys. While it may seem repetitive to mention surveys twice, it is important to differentiate between the broader research technique (point 7) and the specific method used to collect data (point 8).
The research technique, surveys, encompasses the overall approach of using questionnaires or interviews to collect data from respondents. It represents the methodology chosen to gather information. On the other hand, data collection focuses on the actual process of administering the surveys and collecting responses from the target population.
By including both points, the outline or concept map reflects the distinction between the research technique (surveys) and the specific step of data collection using surveys. This ensures clarity and precision in describing the methodology.
Learn more about technique here: brainly.com/question/29843697
#SPJ11
Suppose you were given $1000 from your uncle. You deposited that money in a bank and added $55 per month.

Answers
ANSWERS
• Equation:, s = 1000 + 55m
,• Equation to save $10,000:, 10,000 = 1000 + 55m
,• Months it takes you to save $10,000:, 164 months
EXPLANATION
You first deposit the $1000 your uncle gave you and then, each month, you add $55. So the first month the account will have,
\(1000+55\)After the second month, it will have,
\(1000+55+55\)And so on. Therefore, the equation that models your savings s after m months is,
\(s=1000+55m\)If we want to find how many months it will take to save $10,000 we have to solve the equation for s = 10,000:
\(10,000=1000+55m\)To solve it, subtract 1000 from both sides of the equation,
\(\begin{gathered} 10,000-1000=1000-1000+55m \\ 9000=55m \end{gathered}\)And divide both sides by 55,
\(\begin{gathered} \frac{9000}{55}=\frac{55m}{55} \\ 163.64\approx m \end{gathered}\)It will take at least 164 months to save $10,000.
Which expression is equivalent to -343-507
-125-150
- 22-150
-125-250
-23-350
Answers
None of the given expressions are equivalent to -343-507. To find the expression that is equivalent to -343-507, we need to simplify the given expression by adding the numbers.
So, -343-507 is equal to -850.
Now, we need to check which of the options is also equal to -850.
If we add -125 and -150, we get -275, which is not equivalent to -850.
Similarly, adding -22 and -150 gives us -172, which is also not equivalent.
However, adding -125 and -250 gives us -375, which is not equivalent either. Finally, adding -23 and -350 gives us -373, which is also not equivalent. Therefore, none of the given expressions are equivalent to -343-507.
Learn more about expression here:
brainly.com/question/9657981
#SPJ11