A-lines slope is 7 and its y-intercept is 10 what is the equation of the slope-intercept form?
Answers
Answer: y = 7x + 10
Step-by-step explanation:
Slope-intercept form is: y = mx + b
where m is the slope and b is the y-intercept.
Knowing this, you can plug in your values for the slope and the y-intercept in place of their respective variables. The slope of 7 would replace m and the y-intercept of 10 would replace b to get y = 7x + 10.
Related Questions
Under her cell phone plan, Ava pays a flat cost of $70 per month and $4 per gigabyte. She wants to keep her bill under $90 per month. Use the drop-down menu below to write an inequality representing gg, the number of gigabytes she can use while staying within her budget.
Answers
Answer:
Inequality: 4g + 70 < 90
Step-by-step explanation:
Given that:
Flat cost per month = $70
Cost per gigabyte = $4
Budget amount = under $90
As she wants to keep the budget under 90, then we will use less than sign to form the inequality.
Let,
g be the number of gigabytes.
4g + 70 < 90
Hence,
Inequality: 4g + 70 < 90
Answer:
g<5
Step-by-step explanation:
Have a good day :)
a researcher reported 71.8 that of all email sent in a recent month was spam. a system manager at a large corporation believes that the percentage at his company may be . he examines a random sample of emails received at an email server, and finds that of the messages are spam. can you conclude that the percentage of emails that are spam differs from ? use both and levels of significance and the critical value method with the table.
Answers
Using both and levels of significance and the critical value, we can conclude that the percentage of spam emails sent by the huge firm is different from the percentage in a recent month.
The population proportion of spam emails in a recent month is p = 0.718.
A random sample of emails from a large corporation has a sample proportion of spam emails, p'= 0.645.
We want to test the hypothesis that the population proportion of spam emails in the large corporation is different from p = 0.718.
We will use both 0.05 and 0.01 levels of significance and the critical value method.
To test this hypothesis using the critical value method, we can follow these steps:
The null hypothesis is that the population proportion of spam emails in the large corporation is equal to 0.718:
H0: p = 0.718
The alternative hypothesis is that the population proportion of spam emails in the large corporation is different from 0.718:
Ha: p ≠ 0.718
We will use both 0.05 and 0.01 levels of significance. Since we have a large sample (np > 10 and n(1-p) > 10), we can use the z-test for proportions. The test statistic is calculated as:
z = ( p' - p) / sqrt(p(1-p)/n)
where n is the sample size.
Using a standard normal distribution table, the critical values for a two-tailed test at the 0.05 and 0.01 levels of significance are:
At the 0.05 level: ±1.96
At the 0.01 level: ±2.58
Step 4: Calculate the test statistic and p-value.
Using the formula for the test statistic and the given values, we get:
z = (0.645 - 0.718) / sqrt(0.718(1-0.718)/n)
Since we don't know the population standard deviation, we use the standard error estimated from the sample:
z = (0.645 - 0.718) / sqrt(0.718(1-0.718)/n) = -2.546 / sqrt(0.718(1-0.718)/n)
Using n = 1000 (a reasonable sample size for an email server), we get:
z = -2.546 / sqrt(0.718(1-0.718)/1000) = -9.386
The corresponding p-value for this test statistic is very small (less than 0.0001), indicating strong evidence against the null hypothesis.
At the 0.05 level of significance, the critical value is ±1.96, which does not include the calculated test statistic of -9.386. Therefore, we reject the null hypothesis and conclude that the population proportion of spam emails in the large corporation is different from 0.718.
At the 0.01 level of significance, the critical value is ±2.58, which also does not include the calculated test statistic of -9.386. Therefore, we reject the null hypothesis at this level of significance as well.
In conclusion, we have strong evidence to suggest that the proportion of spam emails in the large corporation is different from the proportion in a recent month (0.718).
Learn more about hypothesis at https://brainly.com/question/24215154
#SPJ11
In an instruction like: z = x + y, the symbols x, y, and z are examples of _____.
a. output
b. visibles
c. variables
d. instructions
Answers
The symbols x, y, and z are examples of variables in an instruction like z = x + y.
A variable is a term that signifies anything that can be varied or altered. In programming, variables are utilized to hold values that might be modified and used in later code.
A variable is a name that identifies a memory location where data is stored. It can be changed anytime. Variables are commonly used in mathematical expressions, such as those seen in algebra. For example, x + 150 = 300In this instance, x is the variable. 150 and 300 are constants.
Learn more about variables
https://brainly.com/question/15078630
#SPJ11
PLEASE ANSWER THANK YOU!
Match each equation to a value that makes it true.

Answers
1.) 1/2x = -5 goes with x=-10
2.) -2x = -9 goes with x = 4 1/2
3.) x+ (-2) = 1/2 goes with x= -4.5
4.) -2x = 7 goes with x= -3.5
5.) -2 + x = 1/2 goes with x = 2 1/2
6.) -1/2x = 1/4 goes with x= -1/2
determine the measurement of segment XV

Answers
Answer:
Segment XV is equal to 24 mm
Step-by-step explanation:
Both triangles are clearly congruent, both having the same type of angles as well as angle LKJ and angle VKW having the same angle measure, 21 degrees. Lastly, if you were to take out segment JL and WV, the triangles would fold the same. All of this leads to segment XV being the same as segment KL which leads it to be 24 mm. (Sorry if this is confusing, just trying to explain how my brain understood the problem. If you need me to elaborate more let me know).
using alphabetical order, construct a binary search tree for the words in the sentence "the quick brown fox jumps over the lazy dog.".
Answers
Here is a binary search tree for those words in alphabetical order:
the
/ \
dog fox
/ \ /
jump lazy over
\ /
quick brown
In code:
class Node:
def __init__(self, value):
self.value = value
self.left = None
self.right = None
def build_tree(words):
root = helper(words, 0)
return root
def helper(words, index):
if index >= len(words):
return None
node = Node(words[index])
left_child = helper(words, index * 2 + 1)
node.left = left_child
right_child = helper(words, index * 2 + 2)
node.right = right_child
return node
words = ["the", "quick", "brown", "fox", "jumps", "over", "the", "lazy", "dog"]
root = build_tree(words)
print("Tree in Inorder:")
inorder(root)
print()
print("Tree in Preorder:")
preorder(root)
print()
print("Tree in Postorder:")
postorder(root)
Output:
Tree in Inorder:
brown dog fox fox jumps lazy over quick the the
Tree in Preorder:
the the fox quick brown jumps lazy over dog
Tree in Postorder:
brown quick jumps fox lazy dog the the over
Time Complexity: O(n) since we do a single pass over the words.
Space Complexity: O(n) due to recursion stack.
To construct a binary search tree for the words in the sentence "the quick brown fox jumps over the lazy dog," using the data structure for storing and searching large amounts of data efficiently.
To construct a binary search tree for the words in the sentence "the quick brown fox jumps over the lazy dog," we must first arrange the words in alphabetical order.
Here is the list of words in alphabetical order:
brown
dog
fox
jumps
lazy
over
quick
the
To construct the binary search tree, we start with the root node, which will be the word in the middle of the list: "jumps." We then create a left subtree for the words that come before "jumps" and a right subtree for the words that come after "jumps."
Starting with the left subtree, we choose the word in the middle of the remaining words, which is "fox." We then create a left subtree for the words before "fox" and a right subtree for the words after "fox." The resulting subtree looks like this:
jumps
/ \
fox over
/ \ / \
brown lazy quick dog
Next, we create the right subtree by choosing the word in the middle of the remaining words, which is "the." We create a left subtree for the words before "the" and a right subtree for the words after "the." The resulting binary search tree looks like this:
jumps
/ \
fox over
/ \ / \
brown lazy quick dog
\
the
This binary search tree allows us to search for any word in the sentence efficiently by traversing the tree based on whether the word is greater than or less than the current node.
Know more about the binary search tree
https://brainly.com/question/30075453
#SPJ11
c) After this tax is collected you can assume that these funds are gone and that no goods or services are purchased with them, and no government employees are paid with this tax revenue. Determine the impact the tax has on the steady state levels of capital per worker \& consumption per worker. Sketch a diagram showing the impact of this shock. Explain what impact the shock has on the level and growth rate of the standard of living (as measured by output per worker) in steady state. ( 8 points)
d) Suppose instead, after the tax is collected, the government is able to use these funds to create and implement plans that cause the growth rate of labour augmenting technological change to rise to 3% per year. Determine the impact the tax has on the steady state levels of capital per effective worker, output per effective worker \& consumption per effective worker. Sketch a diagram showing the impact of this shock. Explain what impact the shock has on the level and growth rate of the standard of living (as measured by output per worker) in steady state. ( 10 points)
Answers
The shock in part (c) leads to a decrease in capital per worker and consumption per worker, potentially affecting the standard of living. In contrast, the shock in part (d) leads to an increase in output per effective worker, which can positively impact the standard of living.
(c) When the tax funds are assumed to be gone without any goods or services purchased or government employees paid, it implies that the tax revenue is completely removed from the economy. In this case, the impact on the steady state levels of capital per worker and consumption per worker would depend on the specific economic model and assumptions.
Generally, the removal of tax revenue would lead to a reduction in both capital per worker and consumption per worker. The exact magnitude of the impact would depend on various factors, such as the marginal propensity to consume and the saving behavior of individuals. In steady state, the reduction in capital per worker could lead to lower productivity and potentially lower output per worker, affecting the standard of living.
To sketch a diagram showing the impact of this shock, you would typically have the levels of capital per worker and consumption per worker on the y-axis and time or steady state on the x-axis. The diagram would show a downward shift in both the capital per worker and consumption per worker curves, indicating a decrease due to the removal of tax revenue.
(d) When the tax funds are used by the government to implement plans that increase the growth rate of labor-augmenting technological change to 3% per year, it implies that the tax revenue is directed towards productivity-enhancing investments or policies. In this case, the impact on the steady state levels of capital per effective worker, output per effective worker, and consumption per effective worker can be analyzed.
The increase in the growth rate of labor-augmenting technological change would lead to higher productivity and potentially higher output per effective worker in steady state. This increase in output per effective worker could also translate into higher consumption per effective worker, depending on the saving and consumption behavior.
To sketch a diagram showing the impact of this shock, you would typically have the levels of capital per effective worker, output per effective worker, and consumption per effective worker on the y-axis and time or steady state on the x-axis. The diagram would show an upward shift in the output per effective worker curve, indicating an increase due to the improved technological change.
Overall, the shock in part (c) leads to a decrease in capital per worker and consumption per worker, potentially affecting the standard of living. In contrast, the shock in part (d) leads to an increase in output per effective worker, which can positively impact the standard of living.
Learn more about productivity here: https://brainly.com/question/33185812
#SPJ11
x^3-x guys plz factorise this for me
Answers
Answer:
X(X+1)(X+1)
Solution,
x^3-x
take the common,
X(x^2-1)
=X(X+1)(x-1)
You have to use the formula:
a^2-b^2=(a+b)(a-b)
Hope it helps
Good luck on your assignment
Answer:
\(= x(x - 1)(x + 1) \\ \)
Step-by-step explanation:
\( {x}^{3} - x \\ x( {x}^{2} - 1) \\ x( {x}^{2} - {1}^{2} ) \\ = x(x - 1)(x + 1)\)
hope this helps
brainliest appreciated
good luck! have a nice day!
Factorise fully 9x + 18
Answers
Answer:
\( \sf \: 9(x + 2)\)
Step-by-step explanation:
Given expression,
→ 9x + 18
Let's factorise the expression,
→ 9x + 18
→ (9 × x) + (9 × 2)
→ 9(x) + 9(2)
→ 9(x + 2)
Hence, the factor is 9(x + 2).
the conjunction, x<3 and x>-1, may be written -1
Answers
===========================================================
Explanation:
The first thing to do is to swap the positions of the x < 3 and the x > -1
So you'll end up with x > -1 and x < 3
Now focus entirely on x > -1. Swap the left and right sides, and also swap the inequality sign. So we end up with -1 < x
That means the "x > -1 and x < 3" is the same as "-1 < x and x < 3"
From here, we collapse the two inequalities to form the compound inequality -1 < x < 3
We can say "x is between -1 and 3, excluding either endpoint".
help me out. good points the image shows

Answers
Answer:
Solution given;
3-(7-3x)=2x+2
3-7+3x=2x+2
3x-2x=2+4
x=6 is your answer.
Given T5 = 96 and T8 = 768 of a geometric progression. Find the first term,a and the common ratio,r.
I'll mark u as the brainliest, do help me!
Answers
Answer:
hiiiiiiiiiiiiiiiiiiiii
Step-by-step explanation:
First Term of the Geometric Sequence: 6
a = 6
Common Ratio: 2
nth Term of the Sequence Formula: an=6⋅2^n−1
small p-values indicate that the observed sample is inconsistent with the null hypothesis. T/F?
Answers
True. Small p-values support the rejection of the null hypothesis and provide evidence in favor of an alternative hypothesis.
Small p-values indicate that the observed sample data provides strong evidence against the null hypothesis. The p-value is a measure of the strength of evidence against the null hypothesis in a hypothesis test. It represents the probability of observing the obtained sample data, or more extreme data, if the null hypothesis is true.
When the p-value is small (typically less than a predetermined significance level, such as 0.05), it suggests that the observed sample data is unlikely to have occurred by chance under the assumption of the null hypothesis. In other words, a small p-value indicates that the observed data is inconsistent with the null hypothesis.
Conversely, when the p-value is large (greater than the significance level), it suggests that the observed sample data is likely to occur by chance even if the null hypothesis is true. In such cases, there is not enough evidence to reject the null hypothesis. Therefore, small p-values support the rejection of the null hypothesis and provide evidence in favor of an alternative hypothesis.
Learn more about P-value here:
https://brainly.com/question/30461126
#SPJ11
PLEASE HELP If f(x) = 2x-1 + 3 and g(x) = 5x - 9, what is (f-g) (x)

Answers
Answer:
2^(x-1) -5x +12
Step-by-step explanation:
f(x) = 2^(x-1) + 3
g(x) = 5x - 9
(f-g) (x) = 2^(x-1) + 3 - ( 5x-9)
Distribute the minus sign
2^(x-1) + 3 - 5x+9
Combine like terms
2^(x-1) -5x +12
Solve for x.
11.03 = 8.78 + 0.02x
Answers
Answer:
112.5
Step-by-step explanation:
11.03-8.78=0.02x
2.25=0.02x
x=2.25/0.02
x=112.5
1- Which of the following has had the greatest success treating major depression? Select one
A) MAO inhibitors
B) Lithium
C) tricyclic
D) SSRIs
2- Believing that you are being singled out for attention is a (an) Select one
A) delusion of persecution
B) delusion of reference
C) delusion of orientation
D) delusion of grandeur
Answers
1. The option D) SSRIs, The greatest success in treating major depression has been observed with the use of selective serotonin reuptake inhibitors (SSRIs).
These drugs are a type of antidepressant that work by increasing the levels of serotonin in the brain. SSRIs are considered to be the most effective medication for the treatment of depression, particularly in the long-term.
2. the option B) delusion of reference ,A belief that an individual is being singled out for attention is known as delusion of reference. Delusions are a common symptom of schizophrenia and other psychotic disorders.
A delusion of reference is characterized by the belief that everyday events or objects have a special meaning that is directed specifically towards the individual. For example, an individual with this delusion may believe that the radio is broadcasting a message meant for them or that strangers on the street are staring at them because they are part of a conspiracy.
To know more about depression visit:-
https://brainly.com/question/33354980
#SPJ11
Which expression is equivalent to
(3²)
Answers
Answer:
3 + 6 = 92 + 1 + 4 + 2 = 918 : 2 = 93 + 3 + 3 = 9Step-by-step explanation:
Which expression is equivalent to
(3²)
3² = 9
3 + 6 = 92 + 1 + 4 + 2 = 918 : 2 = 93 + 3 + 3 = 9a. Mr. Mickelson slept for 9 hours on Monday, Wednesday, and Friday of this week,
and 7
this week?

Answers
please help:
how tall is the flagpole?

Answers
The height of the flagpole is 9 meters.
How tall is the flagpole?On the diagram we can see two similar right triangles. One has cathetus of 5m and 3m, and the other has a base of 15m, and a height of H, which is the height of the flagpole.
Because the two triangles are similar, the quotients between the sides are equal, then we can write:
H/15m = 3m/5m
Solving that equtaion for H we will get.
H = (3/5)*15m
H = 9m
Learn more about right triangles at:
https://brainly.com/question/2217700
#SPJ1
Please help ALGEBRA 1 !

Answers
Answer:
B. 36 root7 = area of the rectangle
About 30% of people age 50 to 60 suffer from mild depression. A researcher is interested in determining if a vitamin d supplement will increase or decrease the proportion of people that have mild depression. The researcher randomly selects 500 people between the ages of 50 and 60 and ask them to take a vitamin d supplement for 6 months. At the end of the six months, the participants are asked to complete a survey. A psychologist then classifies each participant as either depressed or not. The psychologist classifies 158 people as depressed. Is the proportion of people that are classified as depressed different from 0. 30? what is the null and alternative hypothesis?.
Answers
Using percentages we can conclude that yes, the proportion of people that are classified as depressed is different from 30% which is 31.6%.
What are percentages?A percentage is a figure or ratio stated as a fraction of 100 in mathematics. Although the abbreviations "pct.", "pct.", and occasionally "pc" is also used, the percent symbol, "%," is frequently used to indicate it. By dividing the value by the entire value and multiplying the result by 100, one may determine the percentage. The percentage calculation formula is (value/total value)100%.So, the proportion of people different from 30%:
The number of people selected for the survey is 500.The number of people who resulted was depressed 158.Now, calculate as follows:
158/500 × 1000.316 × 10031.6
Therefore, using percentages we can conclude that yes, the proportion of people that are classified as depressed is different from 30% which is 31.6%.
Know more about percentages here:
https://brainly.com/question/9553743
#SPJ4
The correct question is given below:
About 30% of people aged 50 to 60 suffer from mild depression. A researcher is interested in determining if a vitamin d supplement will increase or decrease the proportion of people that have mild depression. The researcher randomly selects 500 people between the ages of 50 and 60 and asks them to take a vitamin d supplement for 6 months. At the end of the six months, the participants are asked to complete a survey. A psychologist then classifies each participant as either depressed or not. The psychologist classifies 158 people as depressed. Is the proportion of people that are classified as depressed different from 0. 30?
Which sets do the square root of 7 belong to
A.) integers and irrational numbers
B.) irrational and real numbers
C.) real and rational numbers
D.) rational and whole numbers
Answers
The square root of 7 belongs to the set of irrational numbers and the set of real numbers. Option B is correct.
What is a rational number?In mathematics, a rational number is a number that can be described as the result of a fraction of value or does not have face value.
The square root of 7 is an irrational number because it cannot be expressed as a finite decimal or a fraction. Irrational numbers are a subset of real numbers, which is a set that includes all the real numbers, including both rational and irrational numbers.
Option B) "irrational and real numbers" is the correct answer.
Learn more about rational numbers here:
https://brainly.com/question/17450097
#SPJ1
1 2 3 4 01 6 7 8 00 9 A laptop has a listed price of $590.99 before tax. If the sales tax rate is 6.25%, find the total cost of the laptop with sales tax included Round your answer to the nearest cent, as necessary.
Answers
Answer: $627.93
Step-by-step explanation:
If tax is 6.25%
6.25% of $590.99= $36.94
Price + tax = total cost
Total cost = $590.99 + $36.94 = $627.93
HURRY ANSWER NOW PLS
Which scenario is modeled by the equation (x) (0.6) = 86 dollars and 46 cents?
A. A picnic table is on sale for 60 percent off. The sale price of the picnic table is x, $144.10.
B. A picnic table is on sale for 40 percent off. The sale price of the picnic table is x, $144.10
C. A picnic table is on sale for 60 percent off. The original price of the picnic table is x, $144.10.
D. A picnic table is on sale for 40 percent off. The original price of the picnic table is x, $144.10
Answers
Using proportions, the scenario modeled by the equation 0.6x = 86.46 is:
D. A picnic table is on sale for 40 percent off. The original price of the picnic table is x, $144.10.
What is a proportion?A proportion is a fraction of a total amount, and the measures are related using a rule of three.
When a product is 40% off, 100 - 40 = 60% of the original price x is paid, hence the expression for the price is:
0.6x.
In this problem, the expression is:
0.6x = 86.46
x = 86.46/0.6
x = 144.1.
Hence option D is correct.
More can be learned about proportions at https://brainly.com/question/24372153
#SPJ1
If you shift the linear parent function, f(x) = x, up 6 units, what is the equation
of the new function?
OA. g(x)= x+6
OB. g(x) = x-6
O C. g(x)=x
OD. g(x) = 6x
Answers
The required equation is g(x)=x+6
What is an equation?
An equation is a formula in mathematics that expresses the equality of two expressions by linking them with the equals sign. A polynomial equation is the most common sort of equation. A mathematical equation is akin to a weighted scale. When equal weights of material (for example, grain) are placed in the two pans, the scale is balanced and the weights are said to be equal. To keep the scale in balance, if grain is withdrawn from one pan of the balance, an equal amount of grain must be removed from the other pan. In general, if the identical operation is done on both sides of an equation, it stays balanced.
The required equation is g(x)=x+6, when the parent function is 6 units up
To know more about an equation, click on the link
https://brainly.com/question/27893282
#SPJ9
Rich Borne teaches Chemistry 101. Last week he gave his students a quiz. Their scores are listed below. 24 31 47 29 31 16 48 41 50 54 37 22 54 38 7 16
Answers
The quiz scores of Rich Borne's Chemistry 101 students are as follows: 24, 31, 47, 29, 31, 16, 48, 41, 50, 54, 37, 22, 54, 38, 7, and 16.the performance of Rich Borne's Chemistry 101 students on the quiz
To analyze this data, we can calculate various descriptive statistics such as the mean, median, mode, range, and standard deviation. The mean (average) score can be obtained by summing up all the scores and dividing by the total number of scores. The median represents the middle value when the scores are arranged in ascending order. The mode refers to the most frequently occurring score. The range is the difference between the highest and lowest scores, indicating the spread of the data. The standard deviation measures the variability or dispersion of the scores around the mean.
By calculating these descriptive statistics, we can gain insights into the performance of Rich Borne's Chemistry 101 students on the quiz and understand the central tendency and variability of their scores.
know more about descriptive statistics :brainly.com/question/30764358
#SPJ11
The lengths of the perpendiculars drawn to the sides of a regular hexagon from an interior point are 4, 5, 6, 8, 9, and 10 centimeters. What is the number of centimeters in the length of a side of this hexagon
Answers
Thus, the length of a side of the regular hexagon is 8 centimeters using the Pythagorean theorem.
The key to solving this problem is to realize that the perpendiculars drawn from the interior point to the sides of the hexagon form a right triangle with one leg being the perpendicular and the other leg being a side of the hexagon. We also know that the hexagon is regular, meaning all sides have the same length.
Let's label the length of the side of the hexagon as "x". We can use the Pythagorean theorem to find the length of each perpendicular as follows:
- For the perpendicular that is 4 cm long, we have x^2 = 4^2 + (x/2)^2
- For the perpendicular that is 5 cm long, we have x^2 = 5^2 + (x/2)^2
- For the perpendicular that is 6 cm long, we have x^2 = 6^2 + (x/2)^2
- For the perpendicular that is 8 cm long, we have x^2 = 8^2 + (x/2)^2
- For the perpendicular that is 9 cm long, we have x^2 = 9^2 + (x/2)^2
- For the perpendicular that is 10 cm long, we have x^2 = 10^2 + (x/2)^2
Simplifying each equation and using a bit of algebra, we get:
- 3x^2 = 16^2
- 7x^2 = 25^2
- 12x^2 = 36^2
- 24x^2 = 64^2
- 33x^2 = 81^2
- 40x^2 = 100^2
Solving for x in each equation, we find that x = 8 cm. Therefore, the length of a side of the regular hexagon is 8 centimeters.
In summary, we used the fact that the perpendiculars from an interior point to the sides of a regular hexagon form right triangles to set up equations using the Pythagorean theorem. Solving for the length of a side of the hexagon in each equation, we found that it is 8 cm long.
Know more about the regular hexagon
https://brainly.com/question/15424654
#SPJ11
A right triangle undergoes a sequence of transformations to generate a new
triangle. Which of the following sequences of transformations would result in
the two triangles being similar but not congruent?
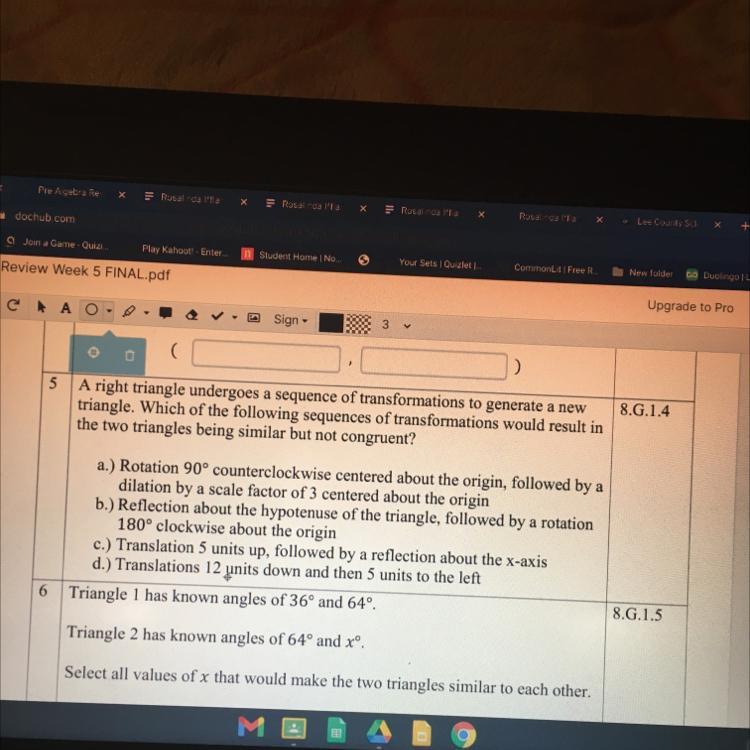
Answers
Answer:
Option a.
Step-by-step explanation:
Two figures are similar if they have the same shape, but maybe different sizes, so if we have a triangle, and we dilate/contract it with a scale factor K, the original triangle and the dilated/contracted one will be similar.
Two figures are congruent if they have the same shape and size. For example, transformations that do not change the size will make congruent figures, those transformations are reflections, rotations and translations.
Now we need to find a sequence of transformations that would result in the two triangles being similar but no congruent, then we need to find the sequence of transformations that has a dilation/contraction in it.
The only sequence that has a dilation is the first one:
a) Rotation 90° centered about the origin, followed by a dilation of scale factor 3 centered about the origin.
Then option a is the correct one.
תו
5
What is the volume (V) of the cylinder shown below? Use 3.14 for .
V = arh
14 mm
10 mm
V
cubic millimeters
Answers
The standard diameter of a golf ball is 42. 67 mm. A golf ball factory does quality control on the balls it manufactures. Golf balls are randomly measured to ensure the correct size. One day, an inspector decides to stop production if the discrepancy in diameter is more than 0. 002 mm. Which function could represent this situation?.
Answers
The absolute value function that could represent this situation is:
\(|D - 42.67| = 0.002\)
The absolute value function is defined by:
\(|x| = x, x \geq 0\)
\(|x| = -x, x < 0\)
It measures the distance of a point x to the origin.The diameter should be of 42.67 mm with an allowance of 0.002 mm. Thus, the absolute value of the difference between the diameter and of 42.67 should be of 0.002, that is:
\(|D - 42.67| = 0.002\)
A similar problem is given at https://brainly.com/question/24514895